您现在的位置是:主页 > news > 网站域名批量查询注册/2345手机浏览器
网站域名批量查询注册/2345手机浏览器
![]() admin2025/7/5 18:45:02【news】
admin2025/7/5 18:45:02【news】
简介网站域名批量查询注册,2345手机浏览器,移动积分兑换商城官方网站,北京百度推广什么是动态SQL? 动态SQL就是指根据不同的条件生成不同的SQL语句。 动态SQL元素和JSTL或基于类似xml的文本处理器相似。 搭建环境 创建表: create table blog( id varchar(50) not null comment博客id, title varchar(100) not null comment博客标题…
什么是动态SQL?
动态SQL就是指根据不同的条件生成不同的SQL语句。
动态SQL元素和JSTL或基于类似xml的文本处理器相似。
搭建环境
创建表:
create table `blog`(
`id` varchar(50) not null comment'博客id',
`title` varchar(100) not null comment'博客标题',
`author` varchar(30) not null comment'博客作者',
`create_time` datetime not null comment'创建时间',
`view` int(30) not null comment'浏览量'
)engine=innodb default charset=utf8创建一个基础工程:
1、导包
<dependencies><!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies>2、编写实体类
@Data
public class Blog {private String id;private String title;private String author;//属性名与字段名不一致,可在setting中配置驼峰命名映射private Date createTime;private int view;
}由于字段与属性不同,在核心配置文件中采用驼峰命名映射:
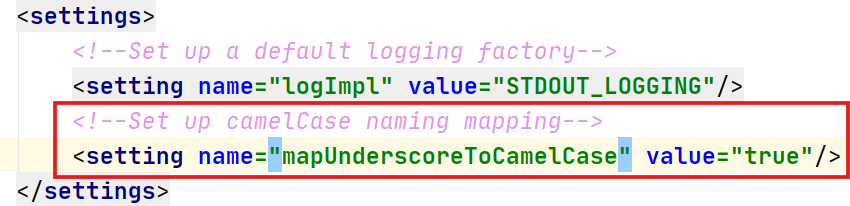
3、编写实体类对应的接口和xml文件
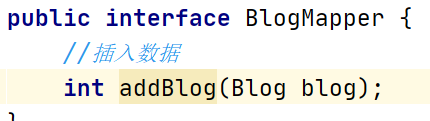
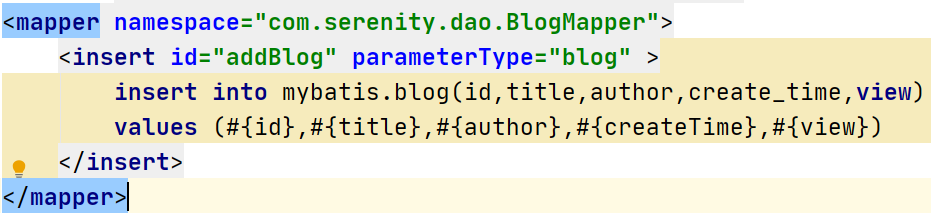
编写自动生成id工具类:
//抑制警告
@SuppressWarnings("all")
public class IDutils {//生成随机idpublic static String getId(){return UUID.randomUUID().toString().replaceAll("-","");}
}编写测试类:
@Testpublic void addBlogTest(){SqlSession sqlSession = MybatisUtils.getSqlSession();BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);Blog blog = new Blog();blog.setId(IDutils.getId());blog.setTitle("Mybatis基础");blog.setAuthor("张三");blog.setCreateTime(new Date());blog.setView(6666);mapper.addBlog(blog);blog.setId(IDutils.getId());blog.setTitle("Web基础");mapper.addBlog(blog);blog.setId(IDutils.getId());blog.setTitle("SQL基础");mapper.addBlog(blog);blog.setId(IDutils.getId());blog.setTitle("Java基础");mapper.addBlog(blog);sqlSession.close();}
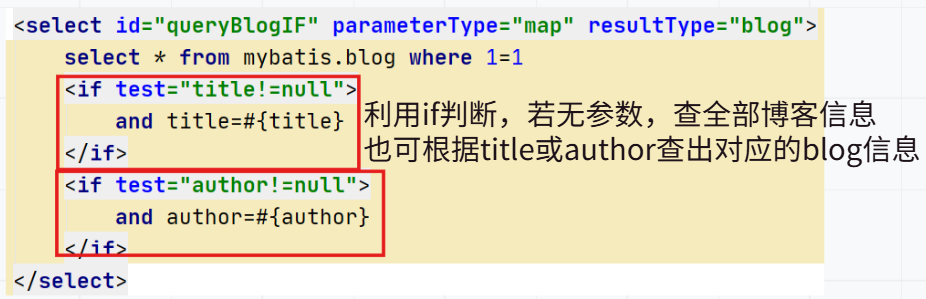
IF语句
编写接口:
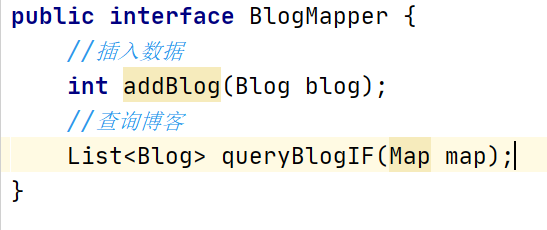
编写接口对应的xml文件:
测试:无参数
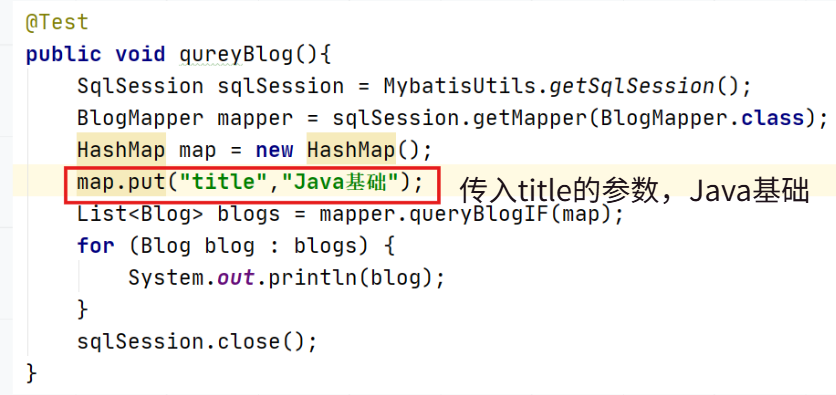
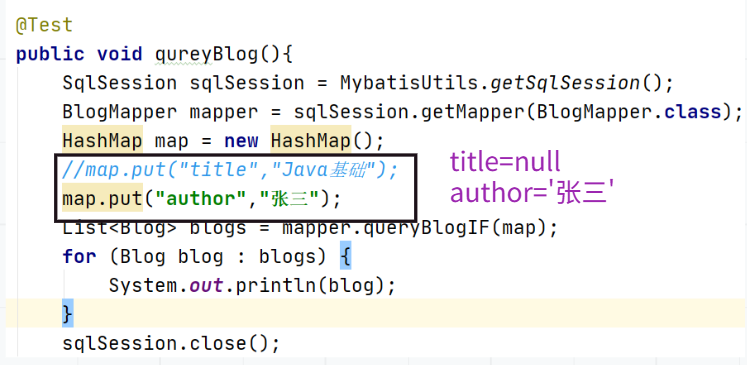
@Testpublic void qureyBlog(){SqlSession sqlSession = MybatisUtils.getSqlSession();BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);HashMap map = new HashMap();List<Blog> blogs = mapper.queryBlogIF(map);for (Blog blog : blogs) {System.out.println(blog);}sqlSession.close();}
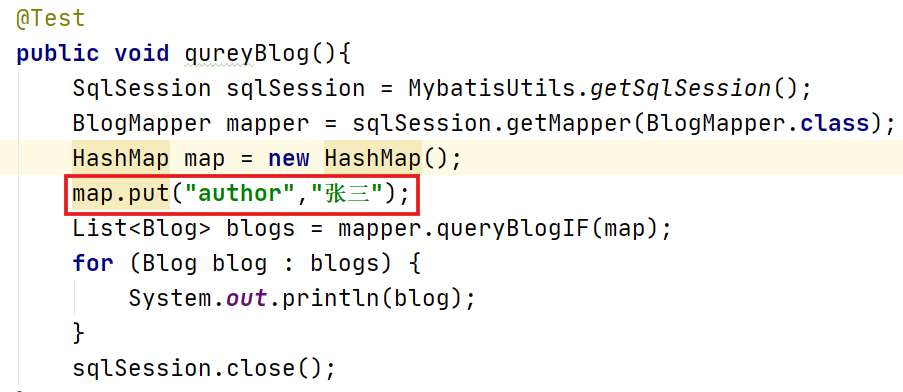
有参数Title:


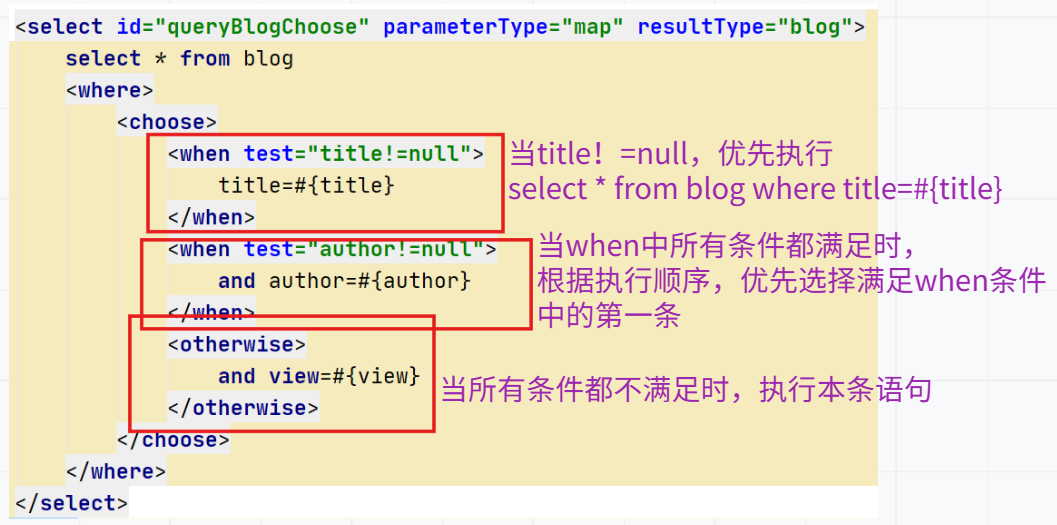
choose(when,otherwise)
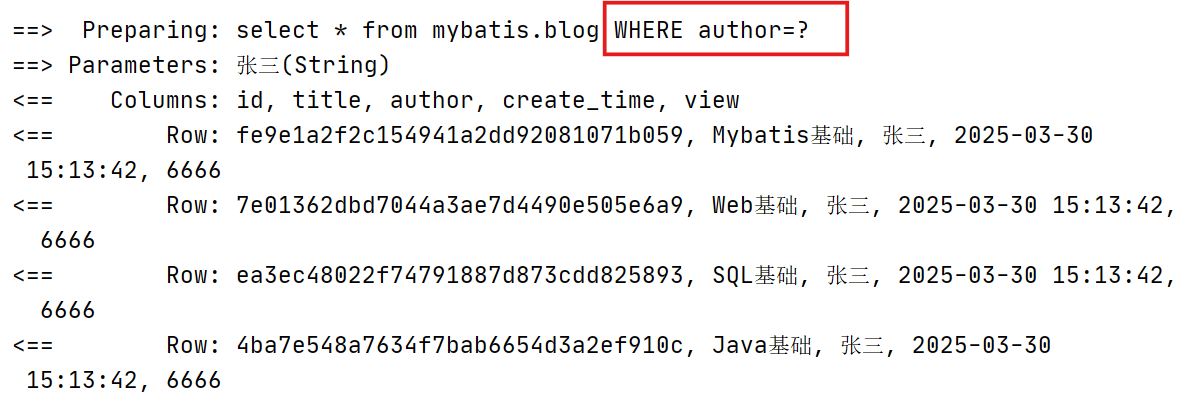
有时我们不想应用到所有的条件语句,只想要其中一项,choose能够满足我们的需求,它有点像Java中的switch语句。它能够按照提供了title就根据title查找,提供了author就按照author查找,若两者都没有提供,就返回所有符号条件的Blog。
编写接口与xml文件:本节使用的where,在下节所描述与解释。

测试:
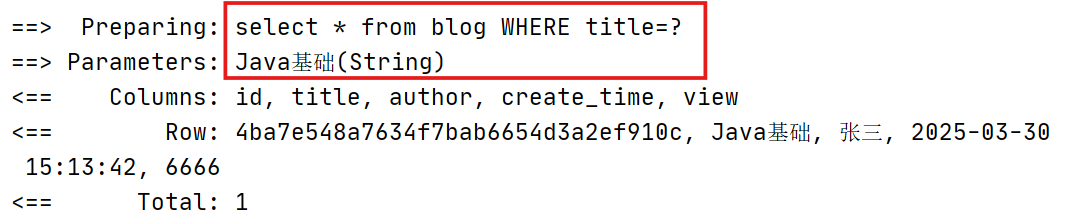
查询view=6666的blog信息
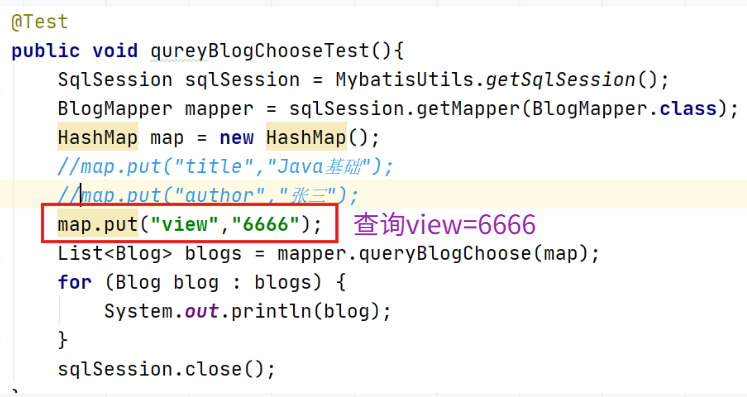

传入title=Java基础,view=666进行查询
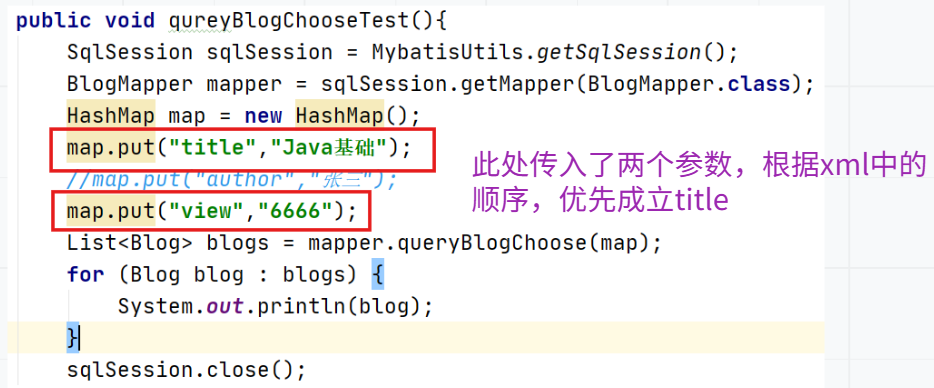
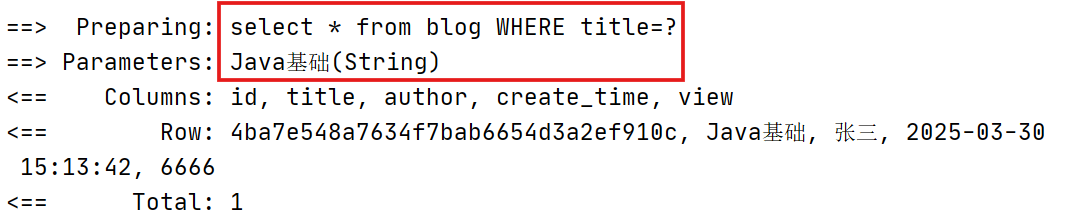
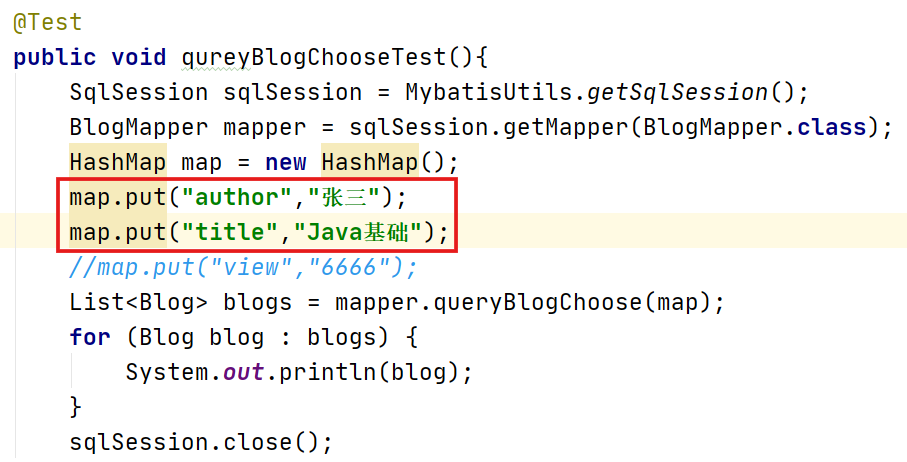
传入author=‘张三’,title='Java基础',在xml中优先执行的是title=#{title}
trim(where,set)
where语句
select * from blog
where
and title like 'someTitle'
执行上述语句,如果仅仅第二个条件匹配,会执行失败。添加一个where标签,减少在if语句中出现where 1=1 的情况。
where元素只会在至少有一个子元素的条件返回SQL子句的情况下才去插入“where”子句,而且,若语句的开头为“and”或“or”,where元素也会将它们去除。rgwhere元素没有按正常套路出牌,我们可以通过自定义trim元素来定制where元素的功能。
改写if语句中的案例,除去where 1=1,加上where标签。
改写如下:

测试:
set更新语句
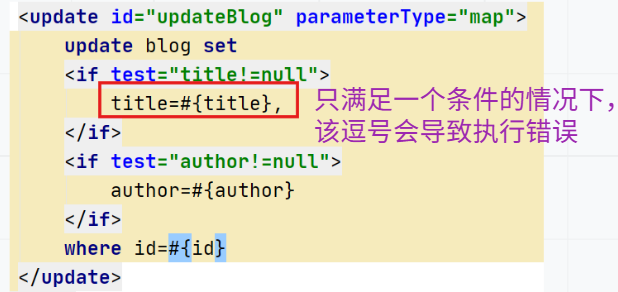
set元素会动态前置set关键字,同时也会删掉无关的逗号,因为用了条件语句之后就很可能会在生成的sql语句的后面留下这些逗号。利用set元素调整上述语句。

测试:
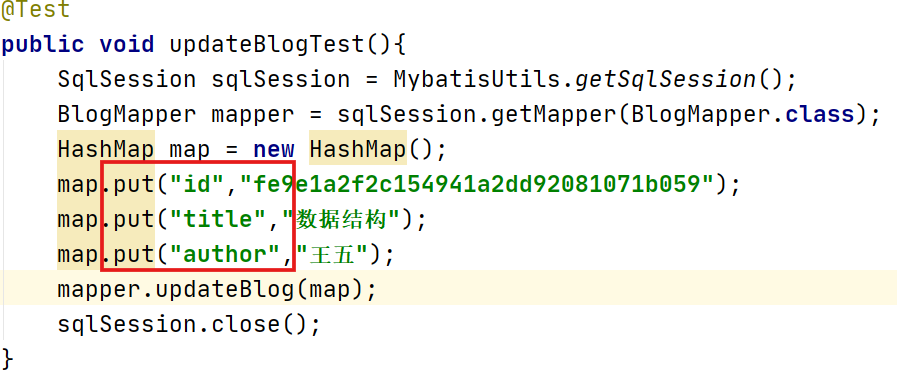

更新author
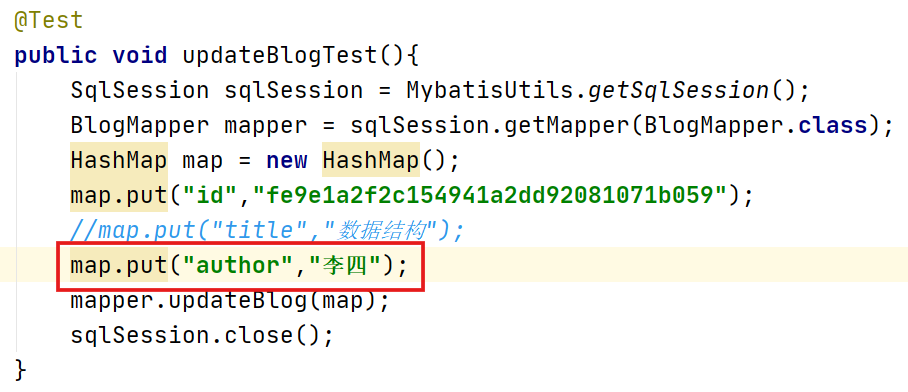

只修改title,让set实现自动去除逗号功能。
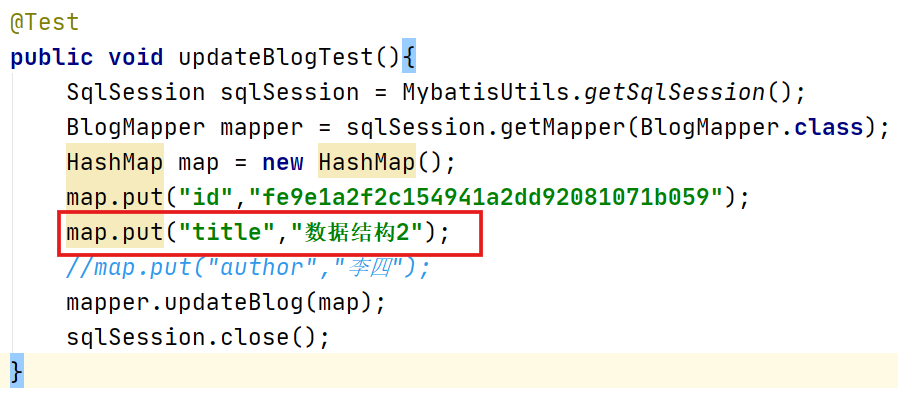

trim定制元素功能
<trim prefix="where" prefixOverrides="and|or">
...
</trim>
上述:利用trim自定义where元素的功能,prefixOverrides属性会忽略通过管道分割的文本序列。它的作用是移除指定在prefixOverrides属性中的内容,并且插入prefix属性中的指定内容。
<trim prefix="set" suffixOverrides=",">
...
</trim>
上述:此处添加了前缀值set,删除了后缀文本逗号。
SQL片段
有的时候,我们会将一些功能的部分抽取出来,方便复用!
抽取IF语句中使用的例子。
1、使用SQL标签抽取公共的部分
<sql id="select_queryBlogIF_if"><if test="title!=null">title=#{title}</if><if test="author!=null">and author=#{author}</if></sql>2、在需要使用的地方使用include标签引用即可
<select id="queryBlogIF" parameterType="map" resultType="blog">select * from mybatis.blog<where><include refid="select_queryBlogIF_if"></include></where></select>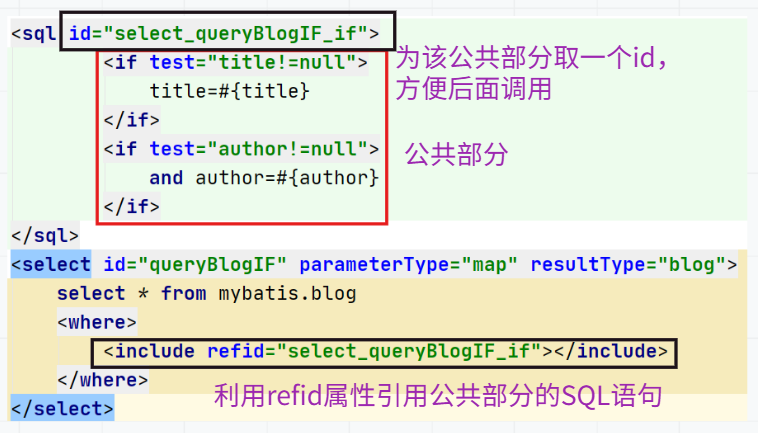
测试结果:

注意事项:
- 最好基于单表来定义SQL片段。
- 不要再片段中写入where标签。
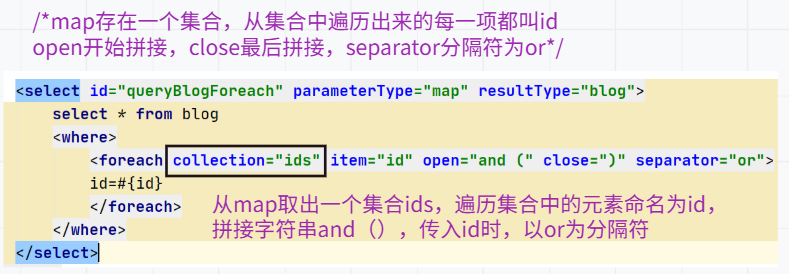
foreach
foreach对一个集合进行遍历,通常在构建IN条件语句的时候。
编写接口:

编写接口的xml文件,以下拼接处的and可去掉
编写测试类:
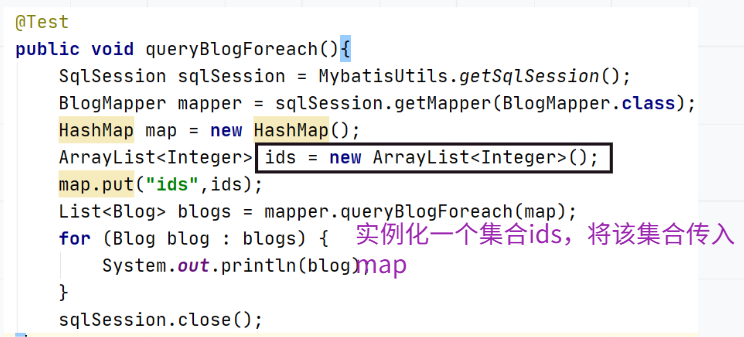
该测试类中集合未传参数。得出结果:

参数参数1,2,3:
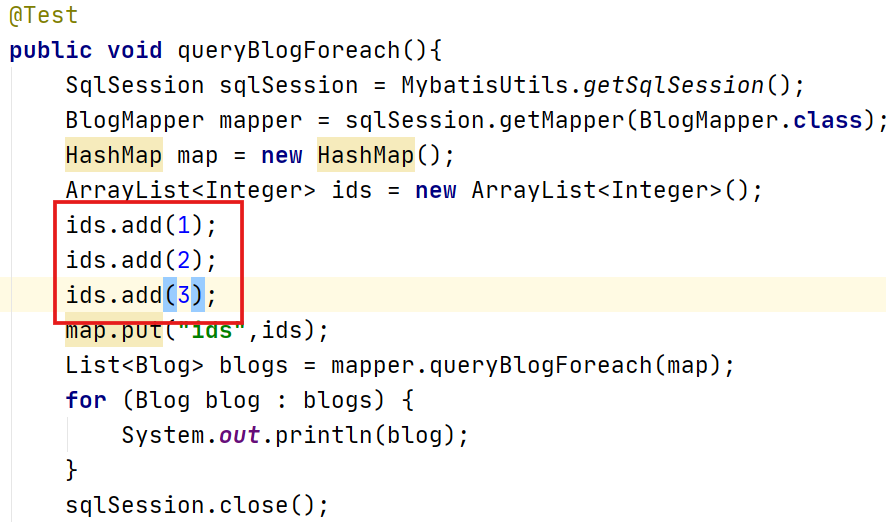
结果:
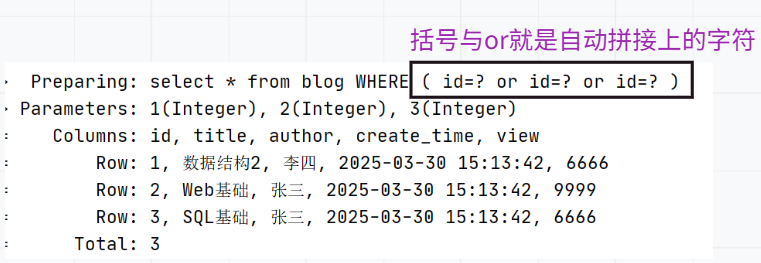
缓存
查询的时候,需要连接数据库,耗费资源。
一个查询的结果,给他暂存存在一个可以直接收取到的地方(内存)
我们再次查询相同的数据时候,直接走缓存,就不用走数据库了。
1、什么是缓存?
- 存在内存中的临时数据。
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
2、为什么使用缓存?
- 减少和数据库的交互次数,减少系统开销,提高系统效率。
3、什么样的数据能使用缓存?
- 经常查询并且不经常改变的数据。(不经常查询但经常改变的数据不适合用缓存)
MyBatis缓存
MyBatis包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。缓存可以极大的提升查询效率。
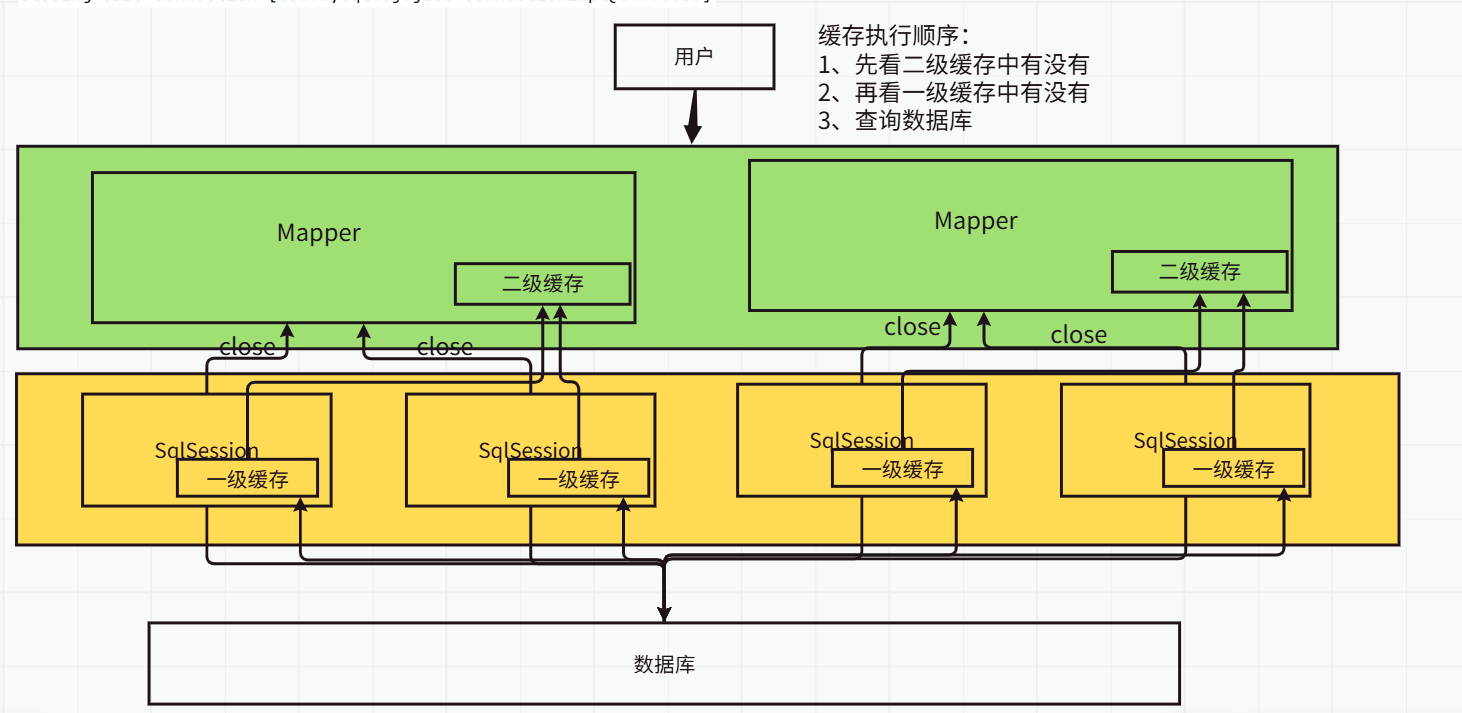
MyBatis系统中默认定义了两级缓存,一级缓存和二级缓存。
- 默认情况下,只有一级缓存开启,(SqlSession级别的缓存,也称为本地缓存)
- 二级缓存需要手动开启和配置,他是基于namespace级别的缓存。
- 为了提高扩展性,MyBatis定义了缓存接口Cache,我们可以通过实现Cache接口来自定义二级缓存。
在MyBatis中存在一些策略,默认的清除策略是LRU
- LRU:最近最少使用,移除最长时间不被使用的对象。
- FIFO:先进先出,按对象进入缓存的顺序来移除它们。
- SOFT:软引用,基于垃圾回收器状态和软引用规则移除对象
- WEAK:弱引用,更积极的基于垃圾收集器状态和弱引用规则移除对象。
一级缓存
一级缓存也叫本地缓存
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 以后如果需要获取相同的数据,直接从缓存中拿,不用必须再去查询数据库
测试在一个Session中查询两次相同记录:
编写接口:
public interface UserMapper {//根据id查询用户User queryUsersByID(@Param("id") int id);
}编写接口的xml文件:
<select id="queryUsersByID" parameterType="_int" resultType="user">select * from user where id=#{id}</select>编写测试:执行两次查询,而且第二次查询语句与第一次一致。
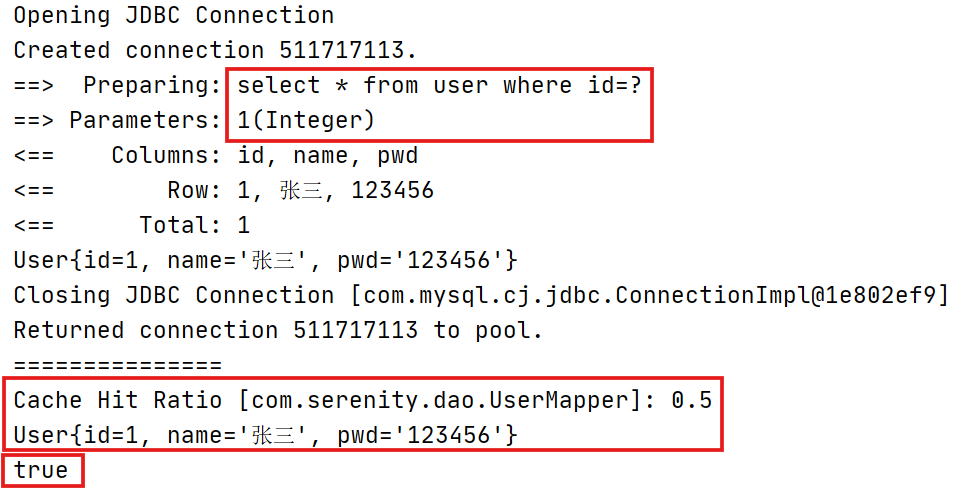
@Testpublic void queryUsersByIDTest(){SqlSession sqlSession = MybatisUtils.getSqlSession();UserMapper mapper = sqlSession.getMapper(UserMapper.class);User user = mapper.queryUsersByID(1);System.out.println(user);System.out.println("===============");User user2 = mapper.queryUsersByID(1);System.out.println(user2);System.out.println(user==user2);sqlSession.close();}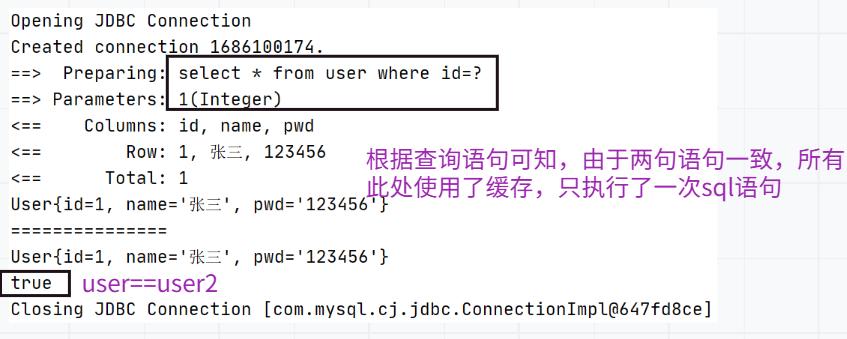
注意:
- 映射语句文件中的所有select语句的结果将会被缓存
- 映射语句文件中的所有insert,update,delete语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU,Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)
- 缓存会保存列表或对象(无法查询方法返回哪种)的1024个引用。
- 缓存会被视为读、写缓存,这意味着获取到的对象并不是共享的,可以安全的被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
增加一个update修改语句,测试上述案例中的sql执行次数
编写接口:

编写接口的xml文件:
<update id="updateUser" parameterType="user">update user set name=#{name},pwd=#{pwd} where id=#{id}</update>测试:
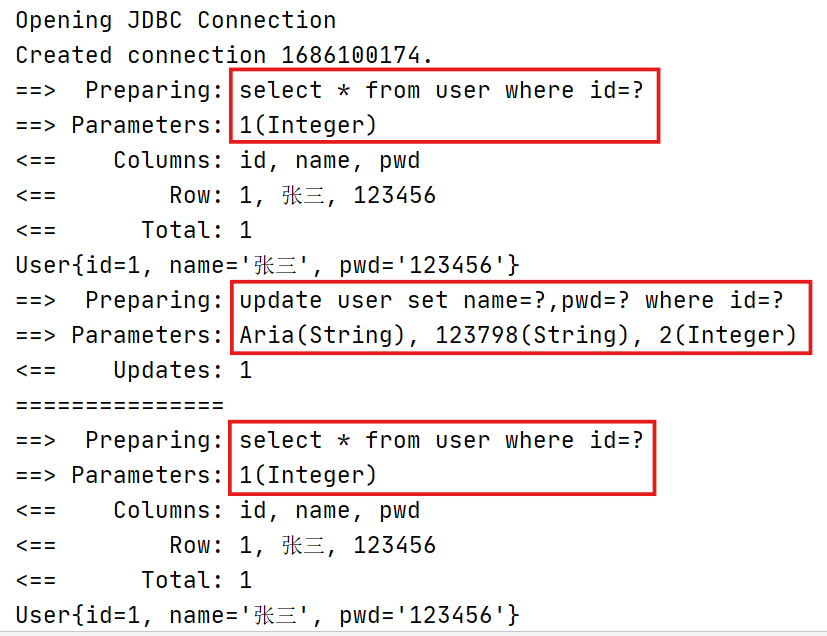
根据上述结果,增删改操作后,可能会改变原来的数据,所以必定会刷新缓存。
手动清理缓存:
sqlSession.clearCache();
一级缓存默认开启,只在一次sqlSession中有效,也就是拿到连接到关闭连接这个区间中。
二级缓存
二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存。
基于namespace级别的缓存,一个名称空间,对应一个二级缓存。
工作机制:
- 一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
- 如果当前会话关闭了,这个会话对应的一级缓存就没了,但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中。
- 新的会话查询信息,就可以从二级缓存中获取内容。
- 不同的mapper查出的数据会放在自己对应的缓存(map)中。
开局全局缓存:在全部配置中setting中设置全局地开启配置文件中的所有映射器已经配置的任何缓存。cacheEnabled,默认值是true,但建议显式的写出。

要开启二级缓存,只需要在sql映射文件中添加一行
<cache/>

也可定制配置:
<cache eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
创建一个FIFO缓存,每个60秒刷新,最多可以存储结果对象或列表的512个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
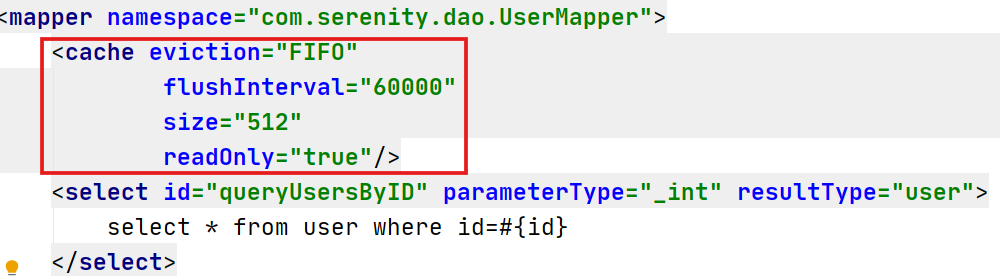
在未开启二级缓存时,创建两个sqlSession查询相同的内容,会执行两次sql。


开启二级缓存,二级缓存是事务性的,这意味着,当SqlSession完成并提交时,或是完成并回滚,但没有执行flushCache=true的insert/delete/update语句时,缓存会获得更新。
缓存原理
对该原理进行测试:










